

Foto de Claudio Schwarz en Unsplash
En tiempos donde la inteligencia artificial alborea en el escenario de lo cotidiano, donde su utilización se afianza día a día y los interrogantes de uso son cada vez mayores, se plantea aquí una guía de lectura nodal para un marco crítico que se proponga analizarla. Esta guía reside en una conceptualización básica, la de inteligencia artificial descentralizada (DeAI). A su vez, presupone una diferenciación inicial sobre la cual partir; recursos de uso centralizado y recursos de uso descentralizado. Así, este post se propone abordar las principales orientaciones de lectura para un fenómeno que promete avanzar cada vez más en la vida humana, la inteligencia artificial, y la gestión de recursos que la sustentan.
Centralización vs. descentralización: definiendo el paradigma tecnológico
Para comprender el alcance y las implicaciones de la inteligencia artificial descentralizada, es fundamental establecer primero la distinción entre sistemas centralizados y descentralizados en el ámbito tecnológico.
Los sistemas centralizados se caracterizan por concentrar el control, procesamiento y toma de decisiones en un punto único o en un número limitado de entidades. En este modelo, una autoridad central —típicamente una empresa o institución— posee y opera la infraestructura, controla los protocolos de acceso, y define las reglas de funcionamiento. Los usuarios dependen completamente de esta entidad central para acceder al servicio, al procesamiento de datos o a funcionalidades específicas.
Adicionalmente, los términos de uso y privacidad suelen expresar (a veces confusamente) qué se hace con los datos y contenido que en el sistema se procesan y quién lo hace. En un sistema centralizado, una empresa o institución decide por el común de sus usuarios que aceptaron previamente las condiciones de uso.
Esto, probablemente es a lo que estés acostumbrado si no has profundizado a consciencia en el manejo de datos en el mundo actual; esto es así porque, porque mayoritariamente en la internet vigente los sistemas centralizados tienen el poder (y la potestad) de imponerse como elección frente al usuario antes otras opciones. Por eso, la práctica consciente de elección es fundamental para acceder a otras fuentes de gestión de recursos virtuales.
Esta predominancia de sistemas centralizados no es meramente accidental, sino el resultado de estrategias deliberadas de control de mercado y sesgos algorítmicos sistemáticos. La investigación académica ha demostrado que los motores de búsqueda dominantes perpetúan sesgos sociales existentes, donde el sesgo algorítmico es consistente con la discriminación social (Lin et al., 2023), afectando particularmente a grupos históricamente desfavorecidos. Además, la concentración monopólica en estos mercados digitales resulta contraproducente para la innovación y calidad del servicio, ya que “una plataforma monopólica dominante resulta en precios más altos y subinversión en innovaciones de mejora de calidad” (Lianos & Motchenkova, 2013). Empresas como Google mantienen su dominancia no solo por superioridad técnica, sino gastando más de $26 mil millones anuales para asegurar su posición como motor de búsqueda predeterminado (Foucart, 2025), lo que evidencia cómo el control de la configuración por defecto se convierte en una herramienta de poder que limita la elección del usuario. Esta realidad subraya la importancia crítica de desarrollar marcos alternativos que promuevan la diversidad de plataformas y la transparencia algorítmica (Mowshowitz & Kawaguchi, 2002), especialmente en contextos donde los efectos de red pueden utilizarse para crear ecosistemas más equilibrados (Schüler & Petrik, 2023).
Un ejemplo ilustrativo de esta dinámica de poder centralizado también se puede observar en los términos de uso de plataformas de inteligencia artificial como OpenAI, donde la empresa establece unilateralmente las condiciones bajo las cuales los usuarios pueden acceder y utilizar sus servicios (OpenAI, 2025). Estos términos determinan no solo qué tipo de contenido puede procesarse, sino también cómo se utilizarán los datos de entrada del usuario, qué derechos retiene la plataforma sobre las interacciones y bajo qué circunstancias puede suspenderse o terminarse el acceso al servicio. El usuario, para acceder a estas herramientas de IA, debe aceptar en bloque estas condiciones sin posibilidad de negociación, ejemplificando cómo los sistemas centralizados ejercen control sobre millones de usuarios mediante un simple clic de aceptación que pocas veces es leído o comprendido en su totalidad. Claro está, el problema principal no está en que una empresa establezca las condiciones bajo las cuáles puede ofrecer sus servicios, sino en cuando estas prácticas empiezan a ser monopólicas, hegemónicas y poco éticas en el uso de datos.
En algunas referencias - como OpenAI (2025) - se utiliza Wayback Machine en lugar de las URLs originales para preservar el estado específico de documentos web que cambian frecuentemente, como términos de uso y políticas de privacidad. Esto garantiza que los lectores puedan acceder exactamente al mismo contenido citado en el momento de la investigación, mejorando la verificabilidad y reproducibilidad del trabajo académico.
Por el contrario, los sistemas descentralizados distribuyen el control y la funcionalidad entre múltiples participantes o nodos en una red. No existe una autoridad única que controle completamente el sistema; en su lugar, las decisiones se toman colectivamente, el procesamiento se distribuye y la resiliencia del sistema no depende de un punto único de fallo. La descentralización representa un paradigma fundamental que desafía los modelos tradicionales de organización jerárquica. A diferencia de los sistemas centralizados, donde existe uno o pocos puntos de control que coordinan todas las operaciones, los sistemas descentralizados distribuyen esta responsabilidad entre múltiples entidades autónomas que colaboran para lograr objetivos comunes (Lua et al., 2005). Esta distribución del poder de decisión no solo reduce la dependencia de infraestructura crítica, sino que también permite una mayor resiliencia ante fallos, ataques o intentos de censura.
En el contexto de las redes informáticas, un ejemplo paradigmático son las redes peer-to-peer (P2P), que representan sistemas distribuidos donde los participantes, denominados peers o nodos, actúan simultáneamente como clientes y servidores (Lua et al., 2005). Estas redes se caracterizan por formar estructuras de red superpuestas (overlay networks) que se auto-organizan sobre la infraestructura existente del protocolo de Internet. Las redes P2P van más allá de los servicios tradicionales cliente-servidor al permitir que cada peer contribuya con recursos (ancho de banda, almacenamiento, capacidad de procesamiento) mientras simultáneamente accede a los recursos proporcionados por otros peers (Lua et al., 2005). Esta simetría en los roles elimina las limitaciones de escalabilidad inherentes a los sistemas centralizados y crea un modelo de compartición de recursos más eficiente y democrático, al menos en teoría.
Existen diferentes tipos de redes P2P según su estructura. Las redes P2P estructuradas utilizan algoritmos determinísticos para organizar los peers y colocar los datos en ubicaciones específicas, empleando técnicas como las tablas hash distribuidas (DHT) que garantizan la localización de cualquier objeto de datos en un número logarítmico de saltos (Lua et al., 2005). Por otro lado, las redes P2P no estructuradas organizan los peers en grafos aleatorios sin un control estricto sobre la colocación de datos, utilizando técnicas como flooding1 o random walks2, lo que las hace más resilientes a la entrada y salida dinámica de peers pero menos eficientes para localizar elementos raros.
Las características fundamentales de los sistemas descentralizados incluyen múltiples dimensiones interconectadas según Lua et al. (2005):
Auto-organización y dinamismo: Los nodos se unen y abandonan la red dinámicamente sin requerir configuración centralizada o aprobación de autoridades. Este proceso implica mecanismos de descubrimiento de peers, establecimiento de conexiones y mantenimiento de la topología de red de forma autónoma. La capacidad de auto-organización permite que el sistema se adapte continuamente a cambios en la disponibilidad de recursos y patrones de uso.
Simetría de roles y reciprocidad: Cada participante puede funcionar tanto como proveedor como consumidor de recursos, eliminando la distinción tradicional cliente-servidor. Esta simetría fomenta un modelo colaborativo donde la contribución de recursos por parte de cada peer beneficia al conjunto del sistema. Sin embargo, esta característica también introduce desafíos relacionados con incentivos para la cooperación y prevención del comportamiento oportunista.
Tolerancia a fallos y resiliencia: La ausencia de puntos únicos de fallo permite que el sistema continúe operando incluso cuando algunos nodos fallen, sean atacados o abandonen la red voluntariamente. Esta resiliencia se logra mediante redundancia de datos, múltiples rutas de enrutamiento y mecanismos de recuperación distribuidos. La capacidad de mantener la funcionalidad ante fallos parciales es una ventaja crítica sobre los sistemas centralizados.
Escalabilidad horizontal: La capacidad del sistema para crecer agregando más nodos sin degradar significativamente el rendimiento global. En teoría, cada nuevo peer que se une a la red contribuye con recursos adicionales, lo que puede mejorar la capacidad total del sistema. No obstante, esto requiere algoritmos eficientes que mantengan las propiedades de enrutamiento y búsqueda independientemente del tamaño de la red.
Resistencia a la censura y autonomía: La distribución del control dificulta el bloqueo, la manipulación o el cierre del sistema por parte de autoridades centrales o actores maliciosos. Esta característica es particularmente relevante en contextos donde la libertad de información y la privacidad son prioritarias. La ausencia de chokepoints centralizados hace que el sistema sea inherentemente más resistente a la interferencia externa.
A pesar de sus ventajas, los sistemas descentralizados y las redes P2P presentan desafíos y limitaciones significativas que deben considerarse en su implementación. En primer lugar, las redes P2P no estructuradas como Gnutella enfrentaron problemas de escalabilidad debido a que los mecanismos de búsqueda basados en flooding consumen excesivo ancho de banda y generan cargas inesperadas en la red, además de que las consultas para contenido raro o poco replicado pueden fallar debido a las limitaciones del horizonte de búsqueda impuestas por el TTL (Time-To-Live) (Lua et al., 2005, p. 85). Por otro lado, aunque las redes P2P estructuradas solucionan parcialmente estos problemas mediante algoritmos determinísticos, introducen complejidad adicional y pueden experimentar alta latencia de búsqueda cuando el camino de la red superpuesta difiere significativamente del camino físico subyacente, lo que puede afectar adversamente el rendimiento de las aplicaciones (Lua et al., 2005, pp. 88-90). Adicionalmente, estos sistemas son vulnerables a diversos ataques de seguridad, incluyendo el retorno de objetos de datos incorrectos a las consultas, corrupción o denegación de acceso a réplicas de datos, suplantación de identidad para almacenar réplicas en peers ilegítimos, y ataques de colusión donde peers maliciosos colaboran para comprometer el sistema (Lua et al., 2005). Finalmente, la gestión de incentivos representa un desafío fundamental, ya que sin mecanismos adecuados para prevenir el comportamiento oportunista (free-riding), la confiabilidad y el valor del sistema pueden verse comprometidos cuando los usuarios se benefician de los recursos compartidos sin contribuir proporcionalmente (Lua et al., 2005).
Los desafíos inherentes a las primeras redes P2P han catalizado el desarrollo de nuevas generaciones de sistemas descentralizados que incorporan mecanismos de incentivos más sofisticados y arquitecturas mejoradas. BitTorrent v2 ha evolucionado con cifrado SHA-256 y optimizaciones que hacen las descargas más rápidas y seguras, manteniéndose como el protocolo P2P dominante (Hipertextual, 2022). Por otro lado, IPFS (Sistema de Archivos Interplanetario) (Protocol Labs, 2024) representa un paradigma más avanzado que puede combinar tecnologías P2P con blockchain para crear un protocolo de hipermedia descentralizado direccionable por contenido, diseñado para hacer la web más rápida, segura y abierta (Desde Linux, 2020). Mientras tanto, las redes blockchain como Bitcoin y Ethereum han resuelto el problema fundamental de los incentivos mediante mecanismos criptoeconómicos que recompensan la participación y penalizan el comportamiento malicioso, creando sistemas de contabilidad distribuidos donde el problema del doble gasto y el free-riding son superados mediante consenso distribuido y recompensas tokenizadas (Bit2Me Academy, 2023). Estas tecnologías modernas demuestran cómo los principios de descentralización han evolucionado desde las limitaciones de las primeras redes P2P hacia ecosistemas más robustos y sostenibles.
De la tecnología a la ciencia: el movimiento descentralizado
Esta dicotomía entre centralización y descentralización trasciende el ámbito puramente tecnológico y se extiende a dominios como la investigación científica. Como se ha analizado en trabajos previos (Pantaleo, 2024a), la ciencia también enfrenta tensiones entre modelos centralizados —controlados por grandes grupos económicos, instituciones hegemónicas y sistemas de financiamiento concentrados— y enfoques descentralizados que buscan democratizar el acceso al conocimiento, diversificar las fuentes de financiamiento, y promover la colaboración abierta.
El diálogo con referentes latinoamericanos en ciencia descentralizada (Pantaleo, 2024b) revela que esta transformación no es meramente técnica, sino que implica una redefinición fundamental de las relaciones de poder, los mecanismos de validación, y los criterios de calidad en la producción de conocimiento. Estas reflexiones sobre la descentralización científica proporcionan un marco conceptual valioso para entender las dinámicas similares que emergen en el desarrollo de la inteligencia artificial.
Inteligencia artificial descentralizada (DeAI)
La inteligencia artificial ha experimentado un crecimiento exponencial en los últimos años, transformando sectores desde la medicina hasta el entretenimiento. Sin embargo, este desarrollo ha estado dominado por grandes corporaciones tecnológicas que concentran el poder computacional, los datos y el control sobre los sistemas más avanzados, como ya se viene describiendo el funcionamiento de sistemas centralizados. En este contexto es pertinente plantear un paradigma alternativo: la inteligencia artificial descentralizada (DeAI).
En este trabajo se pueden ver distintos acrónimos que se utilizan para referir a inteligencia artificial descentralizada. Se usa DzAI (Demazeau & Müller, 1990) o DEAI (Keršič & Turkanović, 2025). Se opta aquí, sin embargo, por DeAI (Cao, 2022) para mantener consistencia con otros acrónimos actuales en el campo de las tecnologías o disciplinas descentralizadas como DeSci (Pantaleo, 2024a) o DeFi. DeAI refiere así a Decentralized (De) Artificial Intelligence (AI).
Revisión histórica: de la distribución a la descentralización
La conceptualización de sistemas de inteligencia artificial no centralizados se remonta a fines de los años 80. Demazeau & Müller (1990) establecieron una distinción seminal entre dos paradigmas fundamentales que sentarían las bases teóricas para los desarrollos posteriores. Su trabajo diferenciaba claramente entre Distributed Artificial Intelligence (DAI) y Decentralized Artificial Intelligence (DzAI), una distinción que resulta crucial para comprender la evolución conceptual del campo.
El DAI tradicional se enfocaba en la solución colaborativa de problemas globales mediante un grupo distribuido de entidades que trabajaban coordinadamente hacia objetivos comunes. Este enfoque requería intercambio mutuo de información constante para lograr un rendimiento colaborativo efectivo, con las entidades distribuidas tanto lógica como geográficamente. En contraste, el DzAI se centraba en la actividad de agentes completamente autónomos operando en un entorno multi-agente, donde cada agente actuaba racionalmente e intencionalmente respecto a sus propios objetivos específicos.
Esta diferenciación temprana es particularmente relevante porque el concepto moderno de IA descentralizada retoma elementos conceptuales del DzAI original: entidades autónomas que persiguen sus propios incentivos, aunque ahora mediados por mecanismos económicos y blockchain que no existían en 1990.
La verdadera transformación del concepto llegó así con la integración de tecnologías blockchain y la visión de democratización de la inteligencia artificial. Montes & Goertzel (2019) presentaron una crítica fundamental al estado actual de la IA, argumentando que la dominación por parte de un oligopolio de mega-corporaciones centralizadas crea un terreno de juego inequitativo con implicaciones potencialmente negativas para la humanidad. Su propuesta de un sistema “distributed, decentralized, and democratized” articuló una visión comprehensiva de cómo la tecnología de ledger distribuido podría transformar fundamentalmente el desarrollo y acceso a servicios de IA. Los autores identificaron problemas sistémicos en el modelo centralizado actual: la necesidad universal de servicios de IA por parte de empresas que carecen del capital necesario para desarrollar sus propios sistemas, y la falta de visibilidad y fuentes de ingresos para desarrolladores independientes de IA. Esta asimetría en el acceso a recursos y oportunidades no solo limita la innovación, sino que también concentra el poder tecnológico en pocas manos, creando dependencias peligrosas y limitando la diversidad de enfoques y aplicaciones. Ya en 2019 los autores comentaban:
Artificial intelligence is a rapidly growing industry with widespread predictions of dramatically changing the economic and labor landscape of the world. By 2020, the global AI market is projected at $47 billion (USD) and the global big data analytics market at $203 billion. To date, the overwhelming majority of AI development is done by a handful of technology mega-corporations (e.g. Facebook, Google, Amazon, IBM, Microsoft, Baidu, etc.). While the world’s population is over 7 billion people, only around 10,000 people in roughly seven countries are writing the code for all of AI (Shen, 2017). By remaining in the hands of a few, the trajectory of AI applications may be significantly compromised. The datasets used to develop such AI and the AIs themselves are biased and may not be generalizable to the wider population, and the companies are beholden to their stakeholder’s interests. The result is a ‘technocracy’ in which the future of one of the most potent set of technologies in the history of humankind is spoken for by a small biased minority (Montes & Goertzel, 2019, p. 1).
Harris & Waggoner (2019), por su parte, materializaron estas ideas teóricas en un framework práctico y funcional para “Decentralized and Collaborative AI on Blockchain”. Su propuesta permitía que múltiples participantes colaboraran para construir datasets de forma distribuida y compartir modelos continuamente actualizados en una blockchain pública mediante contratos inteligentes. Este framework no solo democratizaba el acceso a modelos de IA, sino que también creaba incentivos económicos para la participación y mantenimiento de la calidad de los datos. El sistema propuesto incluía mecanismos sofisticados de validación descentralizada, donde los participantes podían verificar y validar contribuciones de datos sin necesidad de una autoridad central. Esto representaba un avance significativo hacia la autogobernanza de sistemas de IA, donde la calidad y integridad se mantienen a través de incentivos económicos y mecanismos de consenso distribuido.
Sin embargo, el trabajo también identificó limitaciones importantes en la descentralización completa. Algunos mecanismos de incentivos requerían autoridades externas que proporcionaran conjuntos de datos de prueba y fondos de recompensa, mientras que la validación frecuentemente dependía del modelo existente más que de consenso distribuido puro. Además, las restricciones técnicas de Ethereum, particularmente los altos costos de gas, limitaban la escalabilidad del sistema a modelos simples y datos pequeños, principalmente texto en lugar de aplicaciones complejas como procesamiento de imágenes. El sistema también enfrentaba vulnerabilidades ante agentes maliciosos con recursos suficientes y problemas de datos ambiguos que podían comprometer la calidad del modelo. No obstante, proporcionaron una implementación de código abierto completa que demostró la viabilidad práctica del concepto y estableció las bases para futuras investigaciones en IA colaborativa descentralizada.
Por otra parte, en Cao (2022) se puede ver como se consolidó y expandió significativamente el campo al proporcionar un marco conceptual exhaustivo que situaba la IA descentralizada como un paradigma distinto que trasciende tanto la IA centralizada como la distribuida tradicional (DAI). Su publicación integró el concepto emergente de edge intelligence y exploró las intersecciones sinérgicas con tecnologías transformadoras como blockchain inteligente, Web3, metaverso y ciencia descentralizada (DeSci).
Esta consolidación teórica fue crucial porque estableció la IA descentralizada no como una simple variación técnica de enfoques existentes, sino como un paradigma fundamentalmente nuevo que requiere consideraciones distintas en términos de arquitectura, gobernanza, y filosofía de desarrollo. Cao (2022) argumentó que la complementariedad y metasíntesis entre enfoques centralizados y descentralizados podría desbloquear un nuevo potencial para el desarrollo de sistemas de IA más robustos, equitativos y beneficiosos. El trabajo también exploró cómo la IA descentralizada podría habilitar y promover ecosistemas tecnológicos emergentes desde perspectivas disciplinarias, técnicas, prácticas y más amplias. Esta visión holística reconocía que la descentralización de la IA no es meramente un cambio técnico, sino una transformación que impacta aspectos económicos, sociales y éticos del desarrollo tecnológico.
Para ilustrar la complejidad arquitectónica de este nuevo paradigma, los autores presentaron un mapa conceptual que sintetiza las principales configuraciones de la IA descentralizada. La Figura 1 muestra cinco arquitecturas fundamentales que operan en diferentes niveles de la infraestructura de red: desde sistemas P2P completamente descentralizados en dispositivos finales, hasta configuraciones híbridas que integran dispositivos, edge computing y cloud computing. Esta taxonomía arquitectónica demuestra cómo la IA descentralizada puede adaptarse a diferentes contextos operacionales, ya sea mediante el intercambio de datos, el intercambio de modelos, o configuraciones híbridas que optimizan tanto la privacidad como la eficiencia computacional.
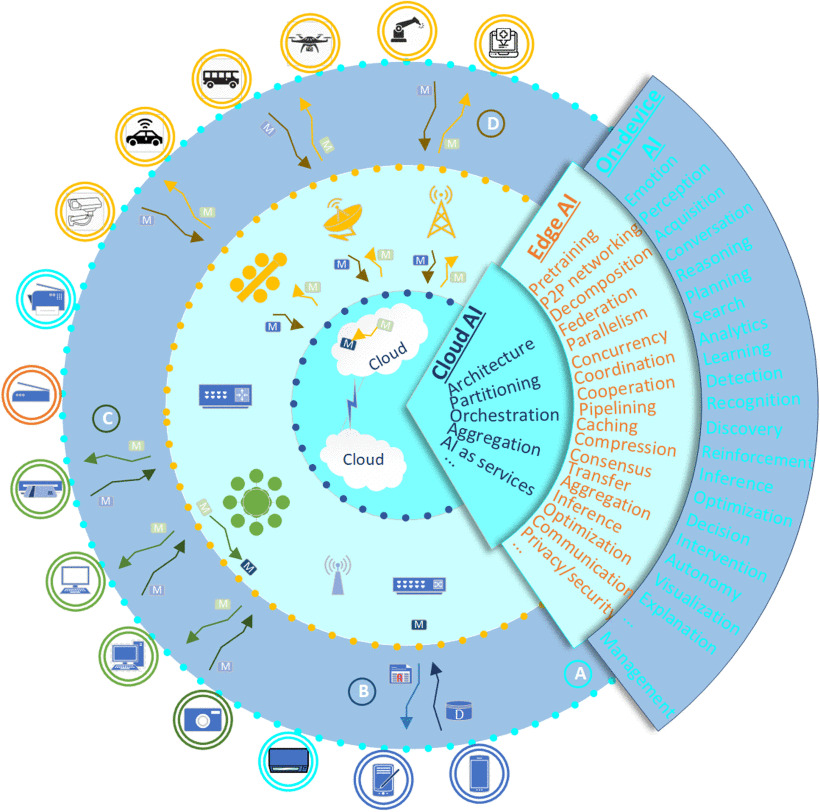
Las cinco arquitecturas ilustradas en la Figura 1 permiten diferentes grados de descentralización y especialización funcional, desde redes completamente distribuidas donde los dispositivos se conectan directamente entre sí, hasta sistemas híbridos que aprovechan las ventajas de cada nivel de la infraestructura de red para optimizar el rendimiento y la privacidad de las aplicaciones de IA.
Finalmente, para consolidar la distinción conceptual entre ambos paradigmas, los autores presentaron una comparación sistemática que abarca los aspectos fundamentales de cada enfoque. La Figura 2 compara las propiedades, características, ventajas y desventajas de la IA centralizada (CeAI) y la IA descentralizada (DeAI) en términos de los aspectos principales de la IA: metodología, objetivos, inteligencia, tareas, datos y recursos, modelos, arquitecturas, procesos, mecanismos, computación, comunicación, toma de decisiones, salida, privacidad y seguridad. Esta comparación también demuestra la necesidad de integrar y equilibrar CeAI y DeAI en sistemas de IA complejos y resolución inteligente de problemas.
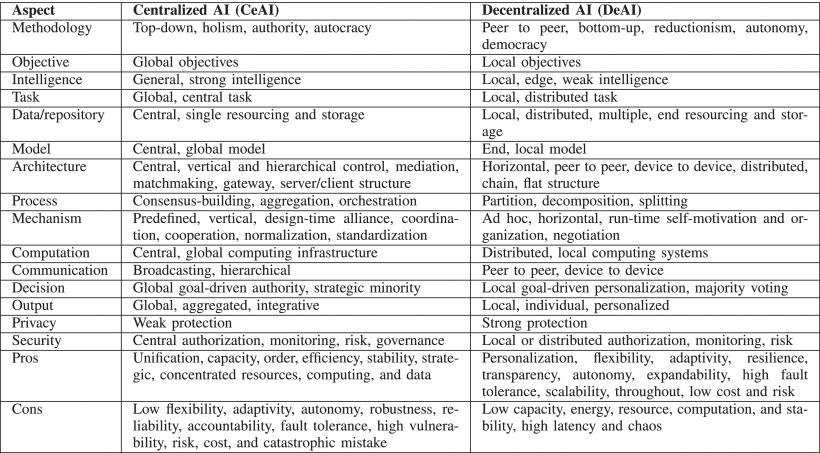
La Figura 2 revela que, más allá de representar paradigmas opuestos, CeAI y DeAI exhiben características complementarias que sugieren la necesidad de enfoques híbridos para sistemas de IA complejos. Esta complementariedad arquitectónica y funcional establece las bases teóricas para el desarrollo de sistemas que puedan aprovechar las fortalezas de ambos paradigmas según los requisitos específicos de cada aplicación.
Estado actual, características e implementaciones de inteligencia artificial descentralizada (DeAI)
El campo de la IA descentralizada ha experimentado una evolución conceptual significativa que requiere un análisis sistemático de sus componentes fundamentales. Keršič & Turkanović (2025) realizaron una revisión sistemática de la literatura que analizó 71 estudios para identificar los bloques constructivos esenciales de los sistemas DeAI. Su investigación adoptó un enfoque bottom-up3, categorizando los componentes técnicos fundamentales que constituyen las redes y soluciones de IA descentralizada. El estudio de Keršič y Turkanović distingue claramente entre los paradigmas históricos de inteligencia artificial distribuida y los enfoques modernos de descentralización. Mientras que el Distributed AI (DAI) tradicional y los Multi-Agent Systems (MAS) se desarrollaron desde los años 70 para distribuir computación pero manteniendo control centralizado, la IA descentralizada moderna incorpora principios Web3 fundamentales: descentralización genuina, auto-soberanía, control de datos por parte de usuarios, ausencia de gestión central y privacidad nativa. Los bloques constructivos identificados incluyen componentes de red descentralizada, mecanismos de consenso adaptados para workloads4 de IA, sistemas de incentivos económicos, protocolos de interoperabilidad y arquitecturas de edge intelligence5. Estos componentes trascienden las limitaciones de sistemas centralizados al eliminar puntos únicos de control y crear ecosistemas donde la innovación puede emerger orgánicamente de comunidades diversas.
La integración de edge intelligence representa uno de los avances más significativos en la arquitectura de IA descentralizada. Keršič & Turkanović (2025) identifican que este paradigma permite procesamiento local de IA cerca de las fuentes de datos, reduciendo latencia, mejorando privacidad y disminuyendo dependencias de infraestructuras centralizadas. Esta distribución geográfica del poder computacional no es meramente una optimización técnica, sino un cambio fundamental que habilita aplicaciones previamente impracticables. La edge intelligence se convierte en componente esencial para aplicaciones como procesamiento de IA en tiempo real en dispositivos IoT, vehículos autónomos con capacidades de decisión local y sistemas móviles que operan independientemente de conectividad constante. Esta arquitectura distribuida crea resiliencia sistémica donde la red puede continuar funcionando incluso cuando nodos individuales fallan o son comprometidos.
Los sistemas de IA descentralizada implementan mecanismos de gobernanza donde las decisiones críticas se toman colectivamente a través de procesos de consenso distribuido. Harris & Waggoner (2019) demostraron cómo estos mecanismos pueden funcionar en la práctica, con participantes validando contribuciones de datos y actualizaciones de modelos sin requerir autoridades centrales. Estos sistemas de gobernanza distribuida van más allá de la simple votación; incorporan incentivos económicos sofisticados que alinean los intereses individuales con el bienestar colectivo del sistema. Los mecanismos de Self-Assessment validados por Harris (2020) muestran cómo la calidad puede emerger orgánicamente de la participación incentivizada, creando sistemas autoregulados que mejoran con el tiempo.
Otra característica fundamental es el mantenimiento del control de datos en manos de sus creadores originales, contrastando dramáticamente con modelos centralizados donde corporaciones acumulan vastos datasets propietarios. Montes & Goertzel (2019) identifican esto como crucial para abordar preocupaciones sobre privacidad, monopolización de información y equidad en el acceso a recursos de datos. Este enfoque de soberanía de datos permite nuevos modelos de colaboración donde los participantes pueden contribuir a sistemas de IA sin sacrificar control sobre su información personal o propietaria. Los datos pueden permanecer localmente mientras contribuyen a modelos globales a través de técnicas como federated learning y privacy-preserving computation.
En Harris (2020) se puede abordar una validación empírica comprehensiva de sistemas de IA descentralizada en blockchain, evaluando múltiples modelos de machine learning (Perceptron, Naive Bayes, y Nearest Centroid Classifier) implementados en contratos inteligentes de Ethereum. Su investigación abordó desafíos prácticos críticos que habían sido teorizados pero no probados empíricamente. El estudio evaluó el mecanismo de incentivos Self-Assessment a través de simulaciones extensas usando tres datasets diversos: predicción de actividades deportivas con datos de Endomondo, análisis de sentimientos en reseñas de películas de IMDB y detección de noticias falsas. Esta diversidad de aplicaciones demostró la versatilidad y robustez del enfoque descentralizado across diferentes dominios y tipos de datos. Los resultados empíricos fueron reveladores: los participantes buenos que contribuían datos correctos consistentemente lograban obtener ganancias económicas, mientras que actores maliciosos que intentaban corromper los modelos perdían sus depósitos. Esto demostró que es posible crear sistemas económicamente sostenibles donde la calidad de datos se mantiene a través de incentivos alineados, sin requerir supervisión centralizada. Particularmente significativo fue el hallazgo de que diferentes modelos de machine learning tienen características de costo y rendimiento distintas en entornos blockchain. El modelo Perceptron demostró ser consistentemente el más económico en términos de costos de gas de Ethereum, mientras que modelos más complejos como Naive Bayes requerían consideraciones especiales de optimización para ser viables económicamente.
Sin embargo, investigaciones recientes también han revelado discrepancias significativas entre las promesas teóricas y las realidades de implementación. Mafrur (2025) presenta una evaluación crítica de tokens basados en IA, cuestionando si los proyectos actuales logran verdadera descentralización o simplemente crean una ilusión de descentralización mediante narrativas especulativas. El análisis de Mafrur examina proyectos líderes como RENDER, Bittensor, Fetch.ai, SingularityNET y Ocean Protocol, identificando limitaciones fundamentales en sus arquitecturas técnicas y modelos de negocio. Desde una perspectiva técnica, muchas plataformas dependen extensivamente de computación off-chain, exhiben capacidades limitadas para inteligencia on-chain y enfrentan desafíos significativos de escalabilidad. Desde una perspectiva de negocio, muchos modelos aparentemente replican estructuras de servicios de IA centralizados, simplemente añadiendo capas de pago y governance basadas en tokens sin entregar valor genuinamente novedoso.
Esta evaluación crítica revela una brecha fundamental entre las aspiraciones de descentralización y las implementaciones actuales. Muchos proyectos que se promocionan como IA descentralizada mantienen componentes centralizados críticos, especialmente en las capas de computación y almacenamiento de modelos. La dependencia de infraestructura off-chain socava las garantías de resistencia a censura y verificabilidad que constituyen principios fundamentales de la descentralización genuina.
Los desafíos identificados por estas investigaciones recientes van más allá de problemas técnicos superficiales. Keršič & Turkanović (2025) destacan problemas fundamentales relacionados con privacidad digital, ownership de datos y control que persisten incluso en sistemas ostensiblemente descentralizados. La transferencia de tecnologías de IA desde el ámbito académico hacia aplicaciones del mundo real acelera cada año, pero durante esta transición emergen cuestiones éticas críticas que los enfoques centralizados actuales no pueden abordar adecuadamente. La investigación revela que muchos sistemas enfrentan el trilema de descentralización en IA (Mssassi & Abou El Kalam, 2025): es extremadamente difícil lograr simultáneamente descentralización genuina, performance competitivo y escalabilidad económica. Los trade-offs entre estos objetivos a menudo resultan en compromisos que sacrifican aspectos de descentralización para mantener viabilidad práctica. Mafrur (2025) identifica que los desafíos de escalabilidad son particularmente altos porque las workloads de IA requieren recursos computacionales intensivos que son costosos de distribuir eficientemente. Los mecanismos de consenso tradicionales de blockchain no están optimizados para validar outputs de IA y los intentos de adaptación a menudo introducen centralizaciones ocultas o vulnerabilidades de seguridad.
El camino hacia IA verdaderamente descentralizada requerirá probablemente enfoques híbridos que combinen beneficios de centralización (eficiencia, performance) con garantías de descentralización (resistencia a censura, control de usuarios) de manera más sofisticada que las implementaciones actuales. Esto podría incluir arquitecturas de múltiples capas donde diferentes aspectos del sistema operen con diferentes grados de descentralización según sus requisitos específicos. La evaluación crítica presentada por Mafrur (2025) no descarta el potencial de la IA descentralizada, sino que enfatiza la necesidad de aproximaciones más fundamentadas y evaluación rigurosa. El campo debe evolucionar más allá de narrativas especulativas hacia implementaciones que demuestren valor técnico y social genuino, balanceando aspiraciones de descentralización con viabilidad práctica y beneficios tangibles para usuarios.
Conclusiones
La inteligencia artificial descentralizada (DeAI) representa una frontera emergente con potencial transformador. Aunque enfrenta desafíos técnicos significativos, los avances en computación distribuida, aprendizaje federado y sistemas de incentivos económicos están creando las condiciones para su viabilidad práctica.
El desarrollo de este paradigma no solo tiene implicaciones técnicas, sino que también plantea cuestiones fundamentales sobre el poder, la gobernanza y la equidad en la era de la inteligencia artificial. A medida que estas tecnologías maduren, es probable que veamos una coexistencia entre sistemas centralizados y descentralizados, cada uno optimizado para diferentes casos de uso y valores.
Sin embargo, el análisis presentado revela que el problema fundamental no reside en la inteligencia artificial per se, sino en los modelos de centralización que la sustentan. La concentración de datos en manos de pocas corporaciones tecnológicas, la dependencia de infraestructuras centralizadas para el procesamiento de modelos y la falta de control de los usuarios sobre sus propios datos constituyen los verdaderos desafíos que la IA descentralizada busca abordar.
Los datos han sido últimamente el factor determinante en el desarrollo de sistemas exitosos. Como demuestran los casos analizados, desde las primeras propuestas de Montes & Goertzel (2019) hasta las implementaciones críticas evaluadas por Mafrur (2025), la cuestión central no es desarrollar algoritmos más sofisticados, sino democratizar el acceso a los datos y redistribuir el control sobre las infraestructuras que los procesan. La IA descentralizada emerge así no como una mera innovación tecnológica, sino como una respuesta necesaria a la concentración de poder digital que caracteriza la era actual.
La evolución hacia una IA más descentralizada no es meramente una cuestión técnica, sino una oportunidad para reimaginar cómo desarrollamos, implementamos y gobernamos las tecnologías que están redefiniendo nuestro mundo. En última instancia, el futuro de la inteligencia artificial será determinado por nuestra capacidad de resolver las tensiones entre eficiencia centralizada y autonomía descentralizada, entre innovación acelerada y control democrático. El futuro de la inteligencia artificial podría ser considerablemente más distribuido, democrático y resiliente de lo que las tendencias actuales sugieren, pero solo si logramos abordar la cuestión fundamental de quién controla los datos que alimentan estos sistemas.
En la elaboración de este texto, se empleó inteligencia artificial para la redacción de párrafos, síntesis conceptual, síntesis bibliográfica, generación de metadatos y contenido en formatos MD, YAML y BibTeX. Asimismo, se utilizó para responder consultas del autor orientadas a expandir análisis críticos y perfeccionar la sintaxis. La asistencia fue proporcionada por Claude Sonnet 4 (Anthropic).
Referencias
Notas
Flooding (inundación) es una técnica donde un nodo envía la consulta de búsqueda a todos sus vecinos conectados, que la reenvían a todos sus vecinos, propagándose como ondas en un estanque. Ofrece alta probabilidad de encontrar contenido pero consume mucho ancho de banda debido al tráfico exponencial generado.↩︎
Random walks (caminatas aleatorias) es una técnica donde la consulta “camina” por la red saltando de un nodo a otro de forma aleatoria, siguiendo un camino único en lugar de multiplicarse. Consume menos ancho de banda que flooding pero tiene menor probabilidad de encontrar contenido raro.↩︎
Bottom-up approach se refiere aquí a construir la comprensión de los sistemas DeAI (DEAI en el artículo) partiendo de sus componentes más básicos (bloques de construcción) para luego entender cómo se combinan en arquitecturas más complejas, en lugar de analizar sistemas completos desde el principio.↩︎
Workloads se refiere a las cargas de trabajo computacionales específicas de IA, como entrenamiento de modelos, inferencia y procesamiento de datos, que requieren recursos intensivos y mecanismos de validación distribuida especializados.↩︎
La edge intelligence es un paradigma computacional que ejecuta algoritmos de IA directamente en dispositivos ubicados en el “borde” de la red (smartphones, sensores IoT, cámaras inteligentes), cerca de donde se generan los datos, eliminando la necesidad de enviarlos a servidores centralizados para su procesamiento.↩︎
Reutilización
Derechos de autor
Cómo citar
@misc{pantaleo2025,
author = {Pantaleo, Patricio Iván},
title = {Inteligencia artificial descentralizada (DeAI): perspectivas
de un desarrollo en ciernes},
date = {2025-07-03},
url = {https://patricio.pantaleo.ar/blog/posts/ia-descentralizada},
doi = {10.62059/7k8m3n},
langid = {es}
}